Raft 实现笔记 (6.824 2021 Spring)
November 05, 2021
完成了年初的flag Implement raft & raft based distributed kv store.
背景
放个图证明自己,爱过.
| raft | kvraft | shardkv |
|---|---|---|
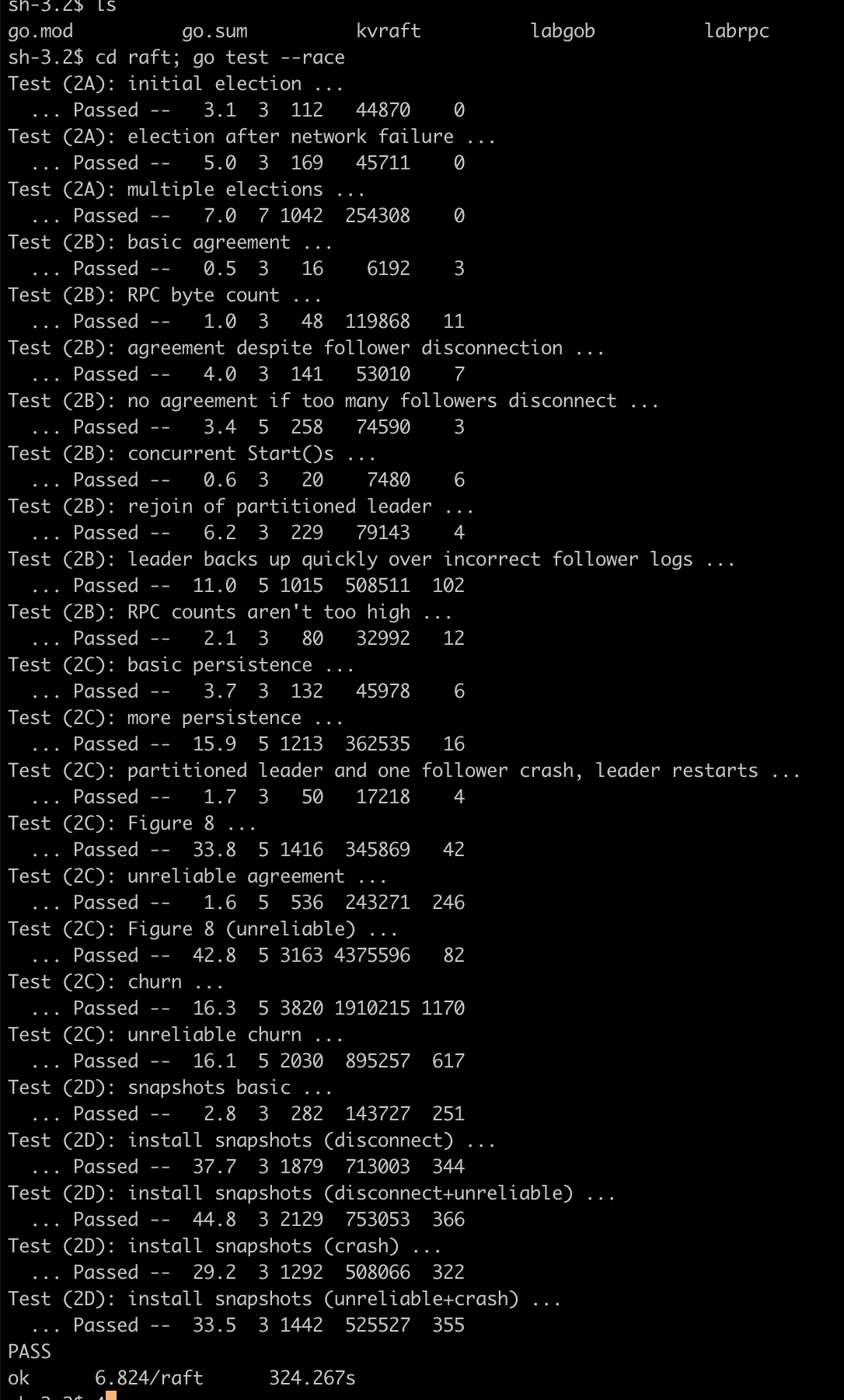 |
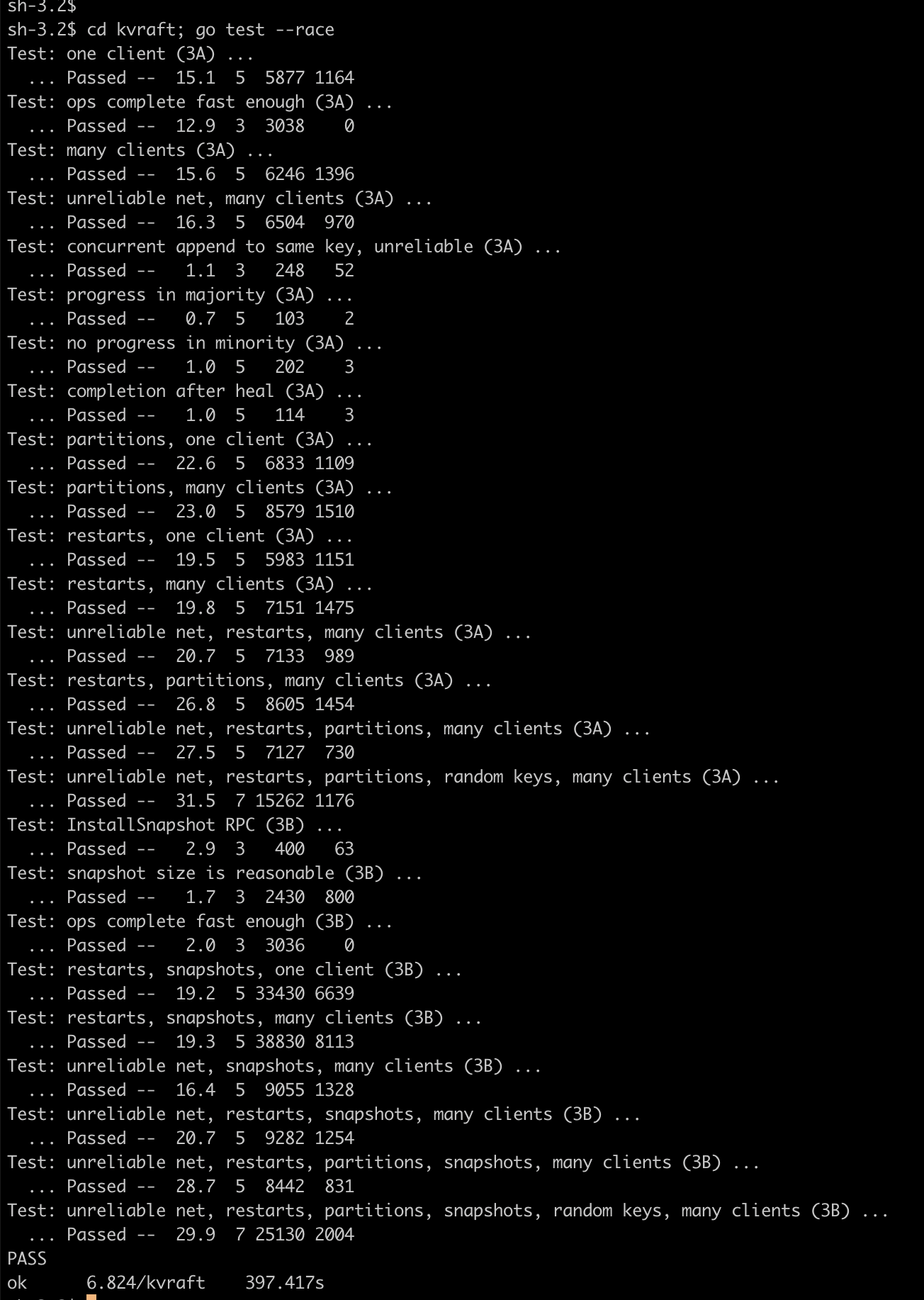 |
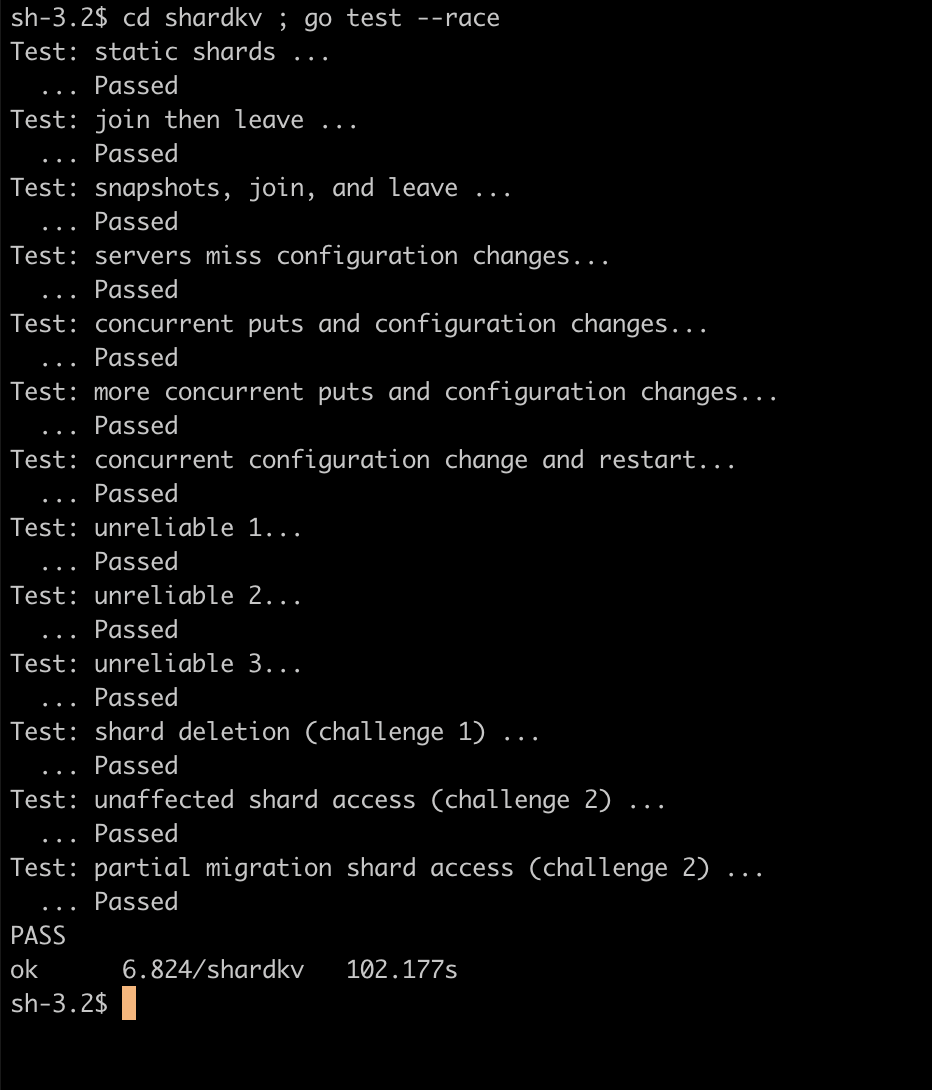 |
目标
学习6.824课程,以及相关的分布式知识,并且基于lab环境
- 完成raft的分布式日志实现
- 完成基于raft log的分布式kvstore
在踩坑的过程中,我碰到了这些问题或者有一些思考
- 跑一次test的时候,没啥问题,但是跑十次可能错一两次
- 碰到死锁怎么办,怎么处理不同的模块之间的锁
- leader在正常工作时,有一个乱入的leader,发送了一个高term请求,如何快速recover
- 用Raft怎么做zookeep或者kafka
- 如何进行performance tuning
- 如何scale
在实现过程中,我都有了一些看法,可以直接跳到最后部分。。。
以下是每个test的实现,我会简单描叙
- 要做的事情
- 技术细节
- 伪代码
- 技术细节的实现
实现
思考
- 跑一次test的时候,没啥问题,但是跑十次可能错一两次
- raft 细节处理
- 出现偶然failure的情况一般都是persist的问题。 Raft paper里面对于commit的条件是,when the log replicate. 在处理heartbeat时,如果不存盘就返回,并且返回leader这个数据当前最新的log位置的话, leader可能就直接apply了。 这个时候如果发生crash, 就会出现问题。
- 但是如果每次heartbeat有新数据需要存盘的话,可能会比较慢,尤其是对于arm主机来说。而且这是一个一次同时挂两台机器,才会出现的问题,所以实际操作中,有些实现是写到内存就返回的。
- 还有一种方式是,异步存数据,但是下一个heartbeat再确认数据replicated, 这样正确性是OK的,但是过不了测试,因为慢。当然,如果实际系统里面,客户端对于latency 不敏感的话,是可以work的。
- 碰到死锁怎么办,怎么处理不同的模块之间锁
- 外部交互
- 每个模块别把锁暴露给别人就可以了,理论上说加锁的scope是这样的 shardkv > kvraft > raft
- leader在正常工作时,有一个乱入的leader,发送了一个高term请求,如何快速recover
- 用Raft怎么实现zookeep或者kafka类似的功能
- Raft的logid与zk的lastId很相似,写入时,我们可以与leader建立一个连接, 然后执行完之后拿到一个logid,记为write_id. 在Get的时候,我们可以与follower建立一个长连接,只要所有的Get请求的idx id比 write_id大,那不就妥了吗。。。
- Kafka 集群,比如3个服务器,一台crash之后,其他server会起来take over, 3台服务器可以挂两个。 kafka的实现是因为它还挂了一个zk, raft也可以在前面挂一个shartctler对peer进行测试,如果3台挂了两台,shardctler可以增加一个新的group, 这个group里面只有一个活着的peer
- 如何做performance tuning
-
对于一个数据来说, commit的时间是
- client —request—> leader
- leader → persist
- leader —heartbeat —> peer
- peer → persist
- peer —hearbeat reply → server
如果为了提升性能, 可以
- persist用ssd或者用memory
- persist用异步来做,这样client latency会增加
- 减少网络latency, 减少peer的数量,peer之后可以接另外的raft group
-
- 如何做scale
- 如果写请求过多,可以做multi raft group
- Get的请求可以放在follower里面,如果对于实时性要求不高的话
- 可以使用多级的raft group,不同级别的raft group可以用不同的策略处理 OnMessage , 也可用不同的粒度来 Save Snapshot